4. MATERIALES Y MÉTODOS
4.1. MATERIALES
4.1.1. Aplicaciones informáticas
4.1.1.1. TermoStat Web 3.0
TermoStatTermoStat se ofrece como una aplicación web accesible en <http://termostat.ling.umontreal.ca/>. es un extractor de términos desarrollado por Drouin (2003) en el Observatoire de linguistique Sense-Texte de la Universidad de Montreal. Actualmente TermoStat trabaja con el inglés, el francés, el español, el italiano y el portugués. Su funcionamiento se basa en la oposición de un texto especializado proporcionado por el usuario con un corpus no especializado (corpus de referencia) con vistas a la identificación de términos (Drouin 2010a).
El corpus de referencia en inglés de TermoStat, lengua en la que realizaremos la extracción, tiene aproximadamente 8.000.000 de palabras y en torno a 465.000 formas. Se trata de un corpus no técnico compuesto por artículos periodísticos de temas variados del periódico canadiense Montreal Gazette publicados en 1989 y textos provenientes del British National Corpus (Drouin 2010a).
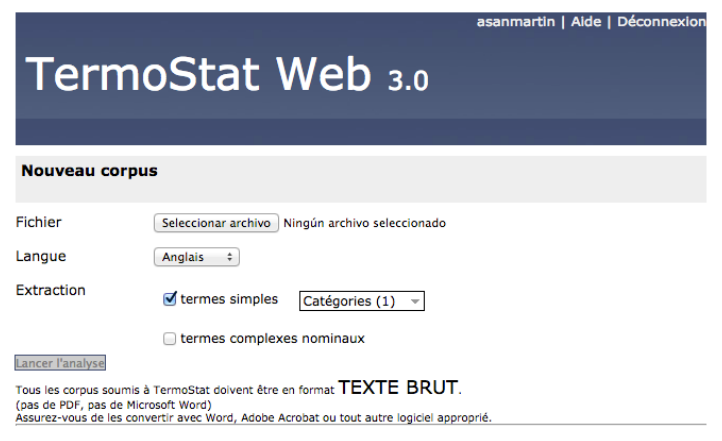
Al cargar un texto para la extracción terminológica (que debe estar en formato de texto plano), el usuario tiene la opción de elegir si desea que los términos que se extraigan sean simples y/o compuestos. Mientras que los términos compuestos pueden ser nominales, en el caso de los términos simples, es posible limitar la extracción a sustantivos, verbos, adjetivos y/o adverbios. La Figura 23 muestra la interfaz de carga de textos en TermoStat Web 3.0.
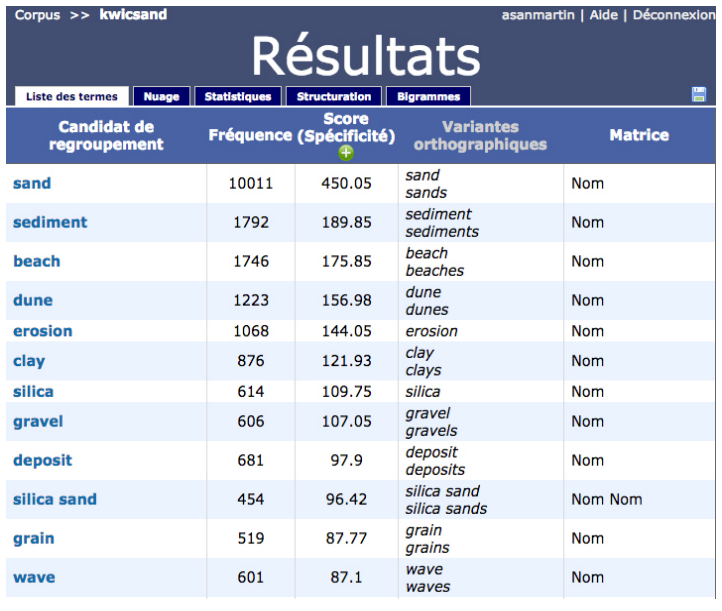
Una vez cargado el texto, la aplicación le devuelve como resultado principal una lista de términos candidatos extraídos del texto. En dicha lista, los términos aparecen acompañados de la siguiente información (Figura 24):
- Fréquence: frecuencia de aparición en el texto provisto por el usuario
- Score: puntuación basada en su frecuencia en el corpus analizado y su frecuencia en el corpus de referencia (Drouin 2010a). Se considera que cuanto más alta la puntuación, mayor pertinencia tendrá el término. El usuario puede elegir qué tipo de fórmula se utiliza para obtener dicha puntuación: especificidad, X2, logaritmo de verosimilitud o logaritmo de la razón de momios.
- Variantes orthographiques: variantes ortográficas y flexiones
- Matrice: categoría gramatical
La lista de términos candidatos junto con la información asociada es exportable. Asimismo, al pulsar en un término candidato se ofrecen las concordancias donde aparece el término en el texto del que se ha extraído el término.
Además de la lista de términos, el usuario puede hacer clic en otras pestañas con funciones adicionales:
- Nuage: Se muestra de manera visual los 100 términos con mayor puntuación a modo de nube de palabras. Cuanto mayor sea la puntuación, más grande aparece el término.
- Statistiques: Se ofrece el número de términos extraídos y estadísticas según la estructura gramatical de los términos.
- Structuration: Se presenta la lista de términos candidatos y cada uno aparece acompañado de aquellos términos compuestos que lo contienen. Al pulsar en el icono amarillo que acompaña a cada término, se accede a más información relacional y se ofrece la posibilidad de generar gráficos con dicha información.
- Bigramme: Se muestra la lista de los bigramas (verbo-sustantivo) más comunes en el texto proporcionado por el usuario. Incluye información sobre la frecuencia y la puntuación de asociación.
4.1.1.2. SketchEngine
SketchEngine (Kilgarriff et al. 2004; Kilgarriff et al. 2014) es una herramienta de análisis de corpus a la que se accede a través de su aplicación web. Una de sus funciones principales y la que inspira su nombre es la de los word-sketches. Si bien, SketchEngine incluye una gran multitud de funciones, nos concentraremos en aquellas de las que hemos hecho uso en este trabajo.
Aunque SketchEngine ofrece numerosos corpus precargados en distintas lenguas o la posibilidad de crear un corpus automáticamente con la herramienta WebBootCat; en este trabajo, hemos cargado nuestros propios corpus especializados (§4.1.2).
Una vez cargado el corpus en la aplicación, el usuario tiene la posibilidad de compilar el corpus para poder hacer uso de todas las funciones que SketchEngine ofrece. El compilado del corpus incluye el etiquetado morfosintáctico del corpus y la aplicación de una gramática de sketches. En nuestro caso, el etiquetador morfosintáctico elegido fue TreeTagger 2.5 (inglés) y la gramática de sketches fue la que ofrece SketchEngine por defecto para ese etiquetador, aunque le añadimos varios nuevos sketches que se describen en §4.2.2.3. Una vez compilado el corpus, es posible definir subcorpus, lo cual configuramos de modo que pudiéramos realizar consultas tanto de todo el corpus como por dominio contextual.
A continuación, repasamos la funciones concordance, word-sketch y word list, que fueron las que empleamos en este trabajo.
Concordance
La función concordance permite consultar directamente el corpus (o los subcorpus) para obtener líneas de concordancias. En la búsqueda simple (simple query), tan solo es necesario escribir una cadena de caracteres para obtener las concordancias. Asimismo, SketchEngine permite realizar búsquedas más avanzadas mediante el lenguaje CQL (Corpus Query Language), lo cual permite, entre otras cosas, emplear etiquetas morfosintácticas, lemas y expresiones regulares. Por ejemplo, la búsqueda «[tag="JJ" & lemma!="hazardous"] [lemma="chemical" & tag=”N.*”]» devuelve todas las concordancias en la que aparece el sustantivo chemical (lo cual incluye, por tanto, el término en singular y plural, y excluye el término usado como adjetivo) precedido de cualquier adjetivo que no sea hazardous.
Al mostrar las concordancias, la aplicación permite, entre otras opciones, aplicar diversos filtros para ordenar los resultados, eliminar aquellos que no sean relevantes, mostrarlos como KWIC (KeyWord In Context) u oración completa, o exportar las concordancias en formato txt o xml.
Word-sketches
Kilgariff et al. (2004: 105) definen un word-sketch como un resumen automático del comportamiento gramatical y colocacional de una palabra dispuesto en una sola página y basado en corpus. Cada word-sketch incluye columnas con listas con las palabras que coocurren con la palabra introducida en la búsqueda en un patrón predeterminado en la gramática de sketch elegida para compilar el corpus. Algunos patrones que vienen incluidos en la gramática de sketch por defecto en inglés aplicables a sustantivos son, por ejemplo:
- object_of: verbos con los que el sustantivo funciona como objeto en el corpus;
- subject_of: verbos con los que el sustantivo funciona como sujeto en el corpus;
- modifier: palabra que funciona como modificador del sustantivo en el corpus;
- modifies: palabra para la que el sustantivo funciona como modificador;
- and/or: otro sustantivo que coocurre con el sustantivo en una enumeración;
En la Figura 25, se reproduce un ejemplo de word-sketches tal y como se muestran en la interfaz de SketchEngine.
Word List
La función Word List permite obtener listas de palabras de un corpus junto con su frecuencia de acuerdo con una gran diversidad de parámetros configurables como el uso de expresiones regulares, lista blanca o negra, comparación con otros corpus, etc.

4.1.2. Descripción de los corpus
En este estudio se utilizaron dos corpus distintos. El primero de ellos es uno elaborado específicamente para este trabajo (que denominamos MULTI, como apócope de multidimensional) y el segundo es el corpus medioambiental monolingüe de inglés elaborado en el marco del proyecto PANACEA.
4.1.2.1. Corpus MULTI
El corpus MULTI se elaboró ad hoc para este trabajo y consta de 15 subcorpus: uno que abarca todo el dominio del medio ambiente (ENV) y 14 de subdominios del medio ambiente:

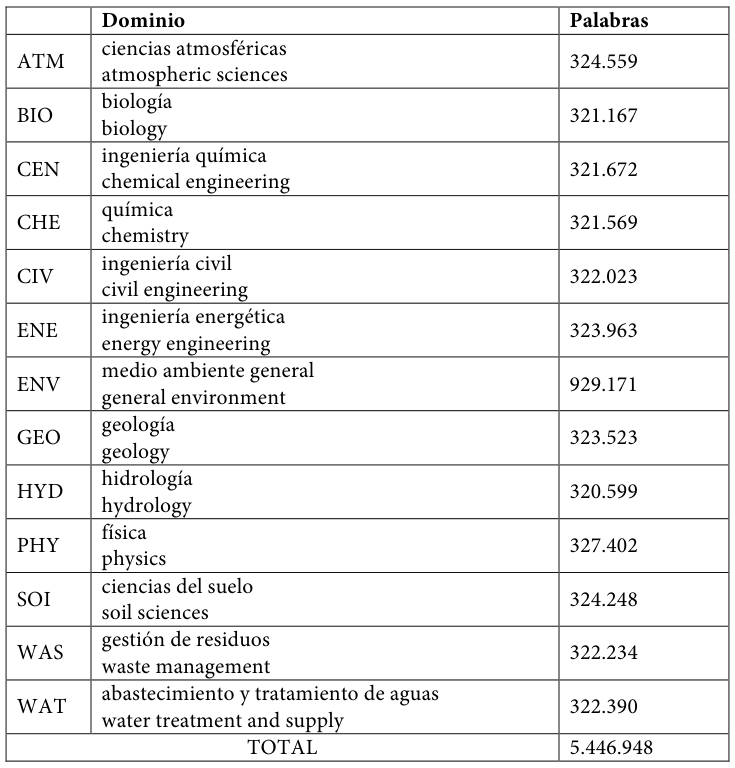
Tabla 18. Número de palabras en cada subcorpus y en total
El subcorpus ENV está compuesto al 100% por manuales semiespecializados de nivel universitario sobre el medio ambiente en general y de una enciclopedia especializada del medio ambiente (ver Anexo 1). Por su parte, todos los subcorpus de dominios están formados en un 62,5% de manuales semiespecializados de nivel universitario del dominio respectivo (aprox. 200.000 palabras) (ver Anexo 1) y un 37,5% de artículos de la Wikipedia (aprox. 120.000 palabras). Tan solo hay una excepción y es el subcorpus de ciencias del suelo que en vez de un 62,5% de manuales semiespecializados, se incluyeron artículos de una enciclopedia sobre ciencias del suelo con textos de características similares a los de un manual, ya que no se encontró ningún manual en formato electrónico de las características deseadas.
La inclusión de manuales semiespecializados y artículos de enciclopedia en el corpus está motivada por el hecho de que, al no estar dirigidos a un público completamente experto, existe mayor probabilidad de que los autores hagan explícitas las características más relevantes de los conceptos que activan en sus textos.
Por su parte, la Wikipedia es una enciclopedia multilingüe en línea colaborativa de libre acceso creada en el año 2001 (Jemielniak 2014: 11). En comparación con la Enciclopedia Británica, sus artículos en inglés son 10 veces más largos (Medelyan et al. 2009: 717) y un controvertido estudio publicado en la revista Nature destacó que su fiabilidad es similar (Giles 2005). Tal y como resumen Mesgari et al. (2015: 10), hay numerosos estudios respecto a su fiabilidad en diversos dominios, cuyo resultado es que la Wikipedia es, por lo general, una fuente fiable de información en diversos dominios, excepto en ciencias de la salud donde los resultados son mixtos.
Como exponen Medelyan et al. (2009), la Wikipedia se utiliza ampliamente en procesamiento del lenguaje natural, recuperación y extracción de información y construcción de ontologías. Además, los trabajos de Vivaldi y Rodríguez (2010a; 2010b; 2011; 2012) demuestran los buenos resultados del empleo de la Wikipedia como fuente para la extracción terminológica.
Para este trabajo, se eligieron manualmente los artículos para cada dominio a partir de las categorías y subcategorías correspondientes en la Wikipedia. El subcorpus ENV no incluye artículos de la Wikipedia porque la cantidad de artículos con un enfoque general sobre el medio ambiente es muy reducida.
4.1.2.2. Corpus PANACEA medioambiental
El corpus monolingüe de inglés medioambiental PANACEADisponible en: <http://catalog.elra.info/product_info.php?products_id=1184>. lo obtuvieron de manera automatizada investigadores de varios países europeos en el marco del proyecto PANACEA (Platform for Automatic, Normalized Annotation and Cost-Effective Acquisition of Language Resources for Human Language Technologies)Para más información sobre PANACEA, se puede visitar la página web del proyecto: <http://www.panacea-lr.eu/>., llevado a cabo como parte del Séptimo Programa Marco de investigación de la Comisión Europea.
Se trata de un corpus exclusivamente en inglés, adquirido automáticamente de Internet con textos clasificados como pertenecientes al dominio del medio ambiente. Contiene en total 50.541.538 palabras repartidas en 28.071 documentos obtenidos a partir de 3.121 sitios web.
Dadas las características del corpus, parte de los documentos que componen el corpus son de tipo divulgativo o de escasa fiabilidad. Sin embargo, su enorme tamaño compensa esas deficiencias para algunas tareas. En este trabajo, este corpus solo se empleó en la extracción de hiperónimos para los conceptos que se definieron en §5.4 porque tras una extracción automática de concordancias, se realizó un filtrado manual.
4.1.3. El léxico científico transdisciplinar
Como ya se indicó en §3.1, la distinción entre palabra y término es una cuestión controvertida. En este sentido, Drouin (2010b) defiende que a caballo entre las unidades léxicas generales y las unidades terminológicas existen unas unidades pertenecientes a lo que él denomina el léxico científico transdisciplinar (LCT) (Drouin 2007; Drouin 2010b):
[O]n considère que le LST transcende les domaines de spécialité et présente un noyau lexical commun significatif entre les disciplines. Le lexique scientifique transdisciplinaire n’est pas saillant dans les textes scientifiques dans la mesure où, contrairement à la terminologie, il se rencontre également dans la langue commune. Par contre, il est au cœur même de l’argumentation et de la structuration du discours et de la pensée scientifique. (Drouin 2007: 45).
El LST de Drouin tiene como antecedentes principales el VGOS (Vocabulaire général d’orientation scientifique) de Phal (1971) en francés y la AWL (Academic Word List) de Coxhead (2000) en inglés. Sin embargo, del VGOS le distingue el hecho de incluir todas las disciplinas científicas, incluidas las ciencias humanas (Drouin 2007: 45). Por su parte, la diferencia de AWL es que el foco de este es la lengua académica (como su propio nombre indica) con vistas a su enseñanza del inglés (Drouin 2007: 46) Asimismo, un proyecto de características similares al del LCT, aunque solamente en francés, es el del Lexique transdisciplinaire des écrits scientifiques de Tutin (2007a; 2007b).
El LCT es un proyecto que se encuentra aún en desarrollo y se centra en el francés y el inglés. Para obtener la primera versión de la LCT en inglés, Drouin (2010b) se basó en dos factores: la distribución en un corpus transdisciplinar y la especificidad de las unidades léxicas en comparación con un corpus de referencia.
El corpus transdisciplinar estaba compuesto por artículos científicos y tesis doctorales pertenecientes a los dominios de antropología, química, informática, ingeniería, geografía, historia, derecho, física y psicología. En total el corpus contenía aproximadamente 4 millones de palabras. Por su parte, el corpus de referencia era una parte del British National Corpus.
Para que una unidad léxica fuera considerada parte del LCT, debía tener un alto nivel de especificidad en el corpus transdisciplinar y aparecer en todos los dominios. Las 10 unidades del LCT más frecuentes en inglés fueron: model, analysis, function, phase, system, structure, method, state, design, interaction (Drouin 2010b: 300). La lista actual completa en inglés está compuesta por 1517 unidadesPuede consultarse en: <http://olst.ling.umontreal.ca/lexitrans/nomenclature.php>..
En este trabajo, haremos uso de la lista de unidades del LCT en inglés para descartarlas de nuestro análisis. Aunque sería necesario un análisis sistemático, las unidades LCT en general no experimentan un nivel suficiente de variación contextual como para que sea necesaria una definición flexible.
El filtrado de las unidades LCT se hizo de manera automática, por lo que se descartaron con ello algunas unidades que, en nuestra opinión, sí podrían necesitar de una definición flexible en el medio ambiente como water, energy o air. Sin embargo, este tipo de casos son aislados.
4.2. MÉTODOS
4.2.1. Selección de conceptos de análisis
El primer paso de nuestro estudio empírico consistió en la obtención de una lista de conceptos que fuesen relevantes simultáneamente en varios dominios contextuales. Para ello, se realizó una extracción terminológica con TermoStat Web 3.0 para cada uno de los 14 subcorpus de dominio contextual del corpus MULTI. La extracción se limitó a términos simples nominales. Cada una de las 14 listas fueron exportadas en formato TXT mediante la función correspondiente en TermoStat Web 3.0. Las listas exportadas de TermoStat contienen, además de los términos candidatos, el número de ocurrencias en el corpus y su puntuación de especificidad, entre otros datos.
A continuación, se realizó una comparación automática de las listas mediante un script PHPEl script PHP lo desarrolló expresamente para este trabajo el investigador Benoît Robichaud, del Observatoire de linguistique Sens-Texte de la Universidad de Montreal.. La lista que devuelve el script organiza los resultados de la comparación en varias columnas: 1) el término candidato; 2) el número de dominios en el que aparece, 3) indicación de si el término está contenido en la lista del LCT; y 4) una columna para cada dominio contextual que contiene el número de ocurrencias en ese dominio.
El script permitía asimismo establecer un umbral mínimo de ocurrencias que un término debía tener en un dominio dado para ser incluido como presente en dicho dominio en la lista. Gracias a ello, se pudo extraer numerosas listas con distintos umbrales para establecer el más adecuado para nuestros fines (a saber, 64 ocurrencias).
La lista final de trabajo estaba formada por los términos que aparecían en tres o más subcorpus de dominios contextuales con una frecuencia superior a 64 ocurrencias. De manera automática se descartaron las unidades pertenecientes al LCT. Manualmente, se excluyeron de la lista las abreviaciones y acrónimos, y los términos polisémicos. Asimismo, se recalculó el número de ocurrencias de algunos términos con variantes ortográficas.
Todos los conceptos representados por los términos de la lista fueron analizados a partir del conocimiento extraído mediante las técnicas que se exponen en el siguiente apartado. Asimismo, haciendo uso de estas mismas técnicas, se procedió a desarrollar la definición flexible de dos conceptos representativos de los fenómenos observados en el análisis de los conceptos.
4.2.2. Extracción del conocimiento
Desde un enfoque descriptivo de la terminología, como es nuestro caso, la metodología empleada para extraer el conocimiento cobra una gran importancia. Dado que nuestra base teórica fundamental es la TBM y los resultados de este trabajo están orientados a su incorporación a EcoLexicon, se siguieron los principios metodológicos que emanan de la TBM y que se aplican actualmente a EcoLexicon. No obstante, añadimos algunos elementos nuevos a los que haremos referencia más adelante.
Como ya se indicó en §2.2.2.4, el rasgo principal de la metodología de extracción del conocimiento de la TBM es su combinación tanto de un enfoque top-down como bottom-up (Faber, León Araúz y Prieto Velasco 2009: 6). El enfoque top-down de la TBM incluye tres elementos principales:
- Extracción de conocimiento a partir de otros recursos terminológicos (bases de datos terminológicas, diccionarios especializados, glosarios, etc.)
- Extracción de conocimiento a partir de otro tipo de obras de referencia especializada (enciclopedias, manuales, libros de texto, etc.)
- Consulta a expertos en el dominio correspondiente71.
Por su parte, el enfoque bottom-up incluye el análisis de corpus, que como veremos en §4.2.2.3, puede tomar distintas formas. Asimismo, cabe destacar que la misma fuente puede emplearse desde un punto de vista top-down o bottom-up. Por ejemplo, las obras de referencia especializadas pueden incluirse en un corpus y, en ese caso, el enfoque adoptado pasa a ser de tipo bottom-up.
4.2.2.1. Análisis de definiciones de otros recursos
La extracción de conocimiento a partir de otros recursos terminológicos es el método top-down principal que se emplea en EcoLexicon. Su principal modalidad es la del análisis de definiciones terminológicas de otros recursos, aunque no es la única, ya que también es posible extraer conocimiento a partir de, por ejemplo, relaciones conceptuales ya codificadas en otra base de datos o cualquier otro elemento de un recurso que represente conocimiento conceptual.
La consulta de otros recursos es una práctica común en lexicografía, pues, como indica Čermák (2003: 19), los lexicógrafos siempre consultan otros diccionarios cuando trabajan en un proyecto lexicográfico. No existen motivos para pensar que la situación no sea similar entre los terminólogos. El auge de la explotación de la información contenida en las definiciones 71 En este trabajo, no se recurrió a la consulta a expertos por el carácter altamente multidisciplinar de esta investigación, ya que se habría requerido contar con un elevado número de expertos, lo cual resultó inviable. Asimismo, los expertos no son siempre capaces de proporcionar la información que necesita el terminólogo (León Araúz 2009: 88) y cada experto posee una conceptualización propia de su dominio (Hameed, Sleeman y Preece 2002: 270) que no se ajusta necesariamente a la convención dentro de esa área de conocimiento.
(u otros elementos) de otros recursos para crear o enriquecer uno propio llegó a partir de la de década de 1980 con la aparición de los diccionarios en formato electrónico (O’Hara 2005: 35). Más de tres décadas de desarrollo y las múltiples aplicaciones que se le han dado han demostrado la enorme utilidad de recurrir al conocimiento ya representado en otros recursos.
Inspirada por el modelo lexemático-funcional (Martín Mingorance 1984; Martín Mingorance 1995; Faber y Mairal Usón 1999), la TBM concibe las definiciones terminológicas como mini-representaciones de conocimiento. Faber y Mairal Usón (1999: 88-91) defienden la utilidad de analizar definiciones de otros recursos de la unidad léxica que se pretende representar, pues, al segmentarlas y contrastar los constituyentes de manera sistemática, podemos obtener información semántica estructurada. Aunque los autores son conscientes de las limitaciones de este método —ya que las definiciones no son siempre satisfactorias— afirman que no se debe dejar de lado, porque si se busca información semántica, los diccionarios son el primer lugar al que hay que acudir:
[D]ictionaries are an extremely valuable resource in any type of lexical research, and not using them because of certain understandable limitations would be a little like throwing the baby out with the bath water. They are undoubtedly the first place one must look into in order to find information about meaning. (Faber y Mairal Usón 1999: 91)
A pesar de que las definiciones no siempre están basadas en estudios de corpus, su sistematicidad es a menudo deficiente, padecen habitualmente de circularidad y algunos autores simplemente copian la definición de otros recursos (León Araúz 2009: 95; Faber et al. 2007: 41), los rasgos más repetidos tienen una gran probabilidad de ser definicionales (Faber 2002).
Además de la búsqueda individual en determinados recursos terminológicos, en este trabajo, se utilizaron cuatro sitios web que permiten consultar las definiciones de numerosos recursos especializados al mismo tiempo:
- MetaGlossaryDisponible en: <http://www.metaglossary.com>.: Al introducir un término en inglés, este sitio devuelve definiciones de cientos de glosarios en Internet. La página de resultados agrupa las definiciones según palabras claves, lo cual a menudo corresponde con sentidos polisémicos del término. Cada definición viene acompañada de la URL de la fuente, lo cual permite comprobar su fiabilidad.
- Oxford ReferenceDisponible en: <http://www.oxfordreference.com>.: Este portal permite consultar con una sola búsqueda cerca de 300 obras de referencia de la editorial Oxford University Press.
- EcoRessourcesDisponible en: <http://termeco.info/ecoressources>.: Este sitio web ha sido desarrollado por el Observatoire de linguistique Sens-Texte de la Universidad de Montreal. Al buscar un término, muestra la definición contenida en diversos recursos terminológicos sobre el medio ambiente como EcoLexicon, DiCoEnviro o las bases de datos terminológicas de la EPA, la EIONET o la FAO.
- OneLookDisponible en: <http://www.onelook.com>.: Este sitio web permite interrogar con una única búsqueda más de 1000 diccionarios o glosarios, muchos de ellos especializados. A diferencia de los tres anteriores, presenta el inconveniente de no mostrar en una única página las definiciones, sino que es necesario visitar cada uno de los enlaces que OneLook proporciona.
4.2.2.2. Consulta de obras de referencia
La extracción de conocimiento a partir de otro tipo de obras de referencia especializada permite al terminólogo adquirir una visión de conjunto del área de conocimiento sobre la que esté trabajando. Cumple una función muy importante en una fase inicial de familiarización y en la resolución de dudas posteriormente. Los textos sobre dominios especializados codifican sistemas conceptuales parciales que el terminólogo puede utilizar como punto de partida. En este sentido, las obras de referencia como enciclopedias, manuales o libros de texto, dado que van dirigidos a un público lego o semiespecializado, suelen codificar de manera más completa los sistemas conceptuales, pues se asume que el receptor no tiene ese conocimiento previo que sí posee el experto. En este trabajo, se hizo un uso extensivo de variedad de obras de referencia a lo largo de todas las etapas.
4.2.2.3. El análisis de corpus
Todo trabajo terminológico se debe basar en gran medida en el análisis de corpus por dos motivos principales (Bourigault y Slodzian 1999: 30):
- Las aplicaciones del trabajo terminológico son casi siempre de tipo textual (traducción, redacción, etc.), así que para que el resultado sea aplicable a nuevos textos, la fuente debe provenir de otros textos.
- En los textos producidos o utilizados por la comunidad de expertos es donde se expresan y se hacen accesibles los conocimientos compartidos por esa comunidad.
Al igual que las definiciones de otros recursos, el análisis de corpus permite extraer información conceptual que posteriormente puede clasificarse y analizarse para caracterizar los conceptos dentro su marco de activación (León Araúz, Faber y Montero Martínez 2012: 106). Además, si los textos incluidos en el corpus son fiables (Buendía y Ureña 2009), la información extraída del corpus se puede utilizar para verificar la obtenida a través de otros medios (Faber, López Rodríguez y Tercedor 2001).
La manera más básica de utilizar un corpus es mediante la lectura manual de las líneas de concordancia del término sobre el que se esté trabajando. Sin embargo, esto consume muchísimo tiempo, por ello existen métodos para analizar y extraer la información de los corpus de manera más eficiente. En este trabajo, además de los word-sketches de SketchEngine, se utilizaron patrones de conocimiento y contextónimos.
4.2.2.3.1. Los patrones de conocimiento
Con el fin de extraer información definicional de un corpus, un enfoque común es la búsqueda de contextos ricos en conocimiento (Meyer 2001). Un contexto rico en conocimiento es un contexto que indica al menos un elemento de conocimiento del dominio que podría ser útil para el análisis conceptual (Meyer 2001: 281). Para encontrar contextos ricos en conocimiento en los corpus, recurre al uso de los patrones de conocimiento, que consisten en patrones lingüísticos y paralingüísticos que transmiten una relación semántica específica (Meyer 2001: 290). En el marco de EcoLexicon, se han utilizado los patrones de conocimiento para analizar corpus tanto de manera manual (Tercedor y López Rodríguez 2008: 171-178; Faber, León Araúz y Reimerink 2011: 376) como (semi)automatizada (León Araúz y Faber 2012; León Araúz 2014; León Araúz y Reimerink 2010).
Los patrones de conocimiento más estudiados son los que transmiten una relación hiperonímica (Auger y Barrière 2008: 4). Algunos ejemplos de tales patrones en inglés son comprise(s), consist(s), define(s), denote(s), designate(s), is/are, is/are called, is/are defined as, is/are known as (Pearson 1998: 140). Los patrones de conocimiento hiperonímicos identifican lo que se ha denominado contextos ricos en conocimiento definitorios (Meyer 2001: 283), expositivos definitorios (Pearson 1998: 135) o, simplemente, contextos definitorios (Malaisé, Zweigenbaum y Bachimont 2005; Sierra 2009; Alarcón Martínez 2009). Los contextos definitorios poseen los mismos componentes que una definición tradicional: definiéndum, genus y, ocasionalmente, differentiae.
Por otro lado, Meyer (2001: 283) denomina contextos ricos en conocimiento explicativos a cualquier otro tipo de contexto rico de conocimiento. Este tipo de contextos pueden ser de tipo causal, funcional, meronímico, etc. Para extraer cada tipo es necesario emplear patrones de conocimiento específicos. Por ejemplo, cause(s), produce(s) y generate(s) son patrones de conocimiento causales (León Araúz y Faber 2012).
En este trabajo, tan solo hicimos uso de patrones de conocimiento de tipo hiperonímico. Se emplearon para la extracción de candidatos a genus. Dicha extracción se realizó de manera automática con SketchEngine mediante la adición de nuevos tipos de word-sketches basados en patrones de conocimiento a la gramática que incluye SketchEngine por defecto en inglés.
A continuación, se reproducen los patrones empleadosLos diez patrones son una ampliación y refinamiento de los tres patrones incluidos en Buendía, Sánchez Cárdenas y León Araúz (2014). tal y como se codificaron para su uso en este trabajo, acompañados de una explicación de cada elemento y de ejemplos extraídos del corpus MULTI.
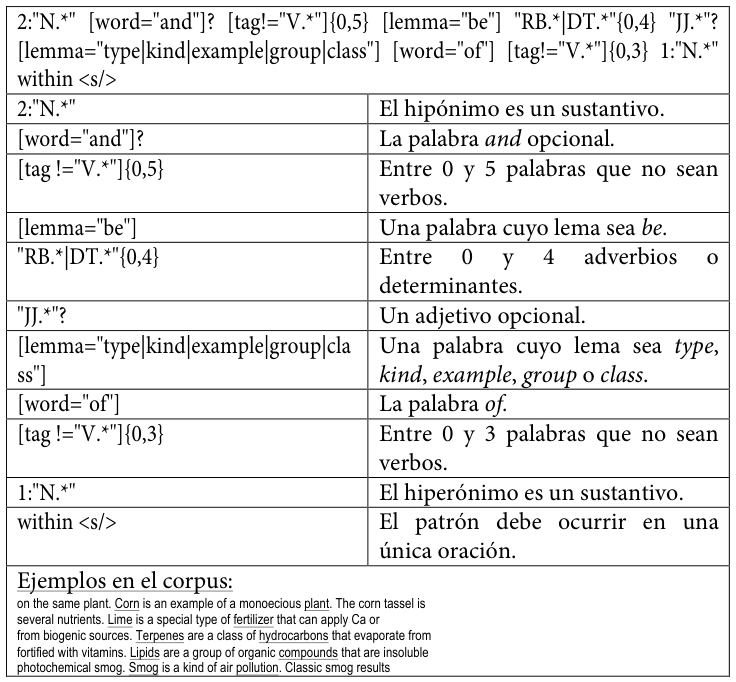
Tabla 19. Primer patrón de conocimiento hiperonímico codificado para SketchEngine
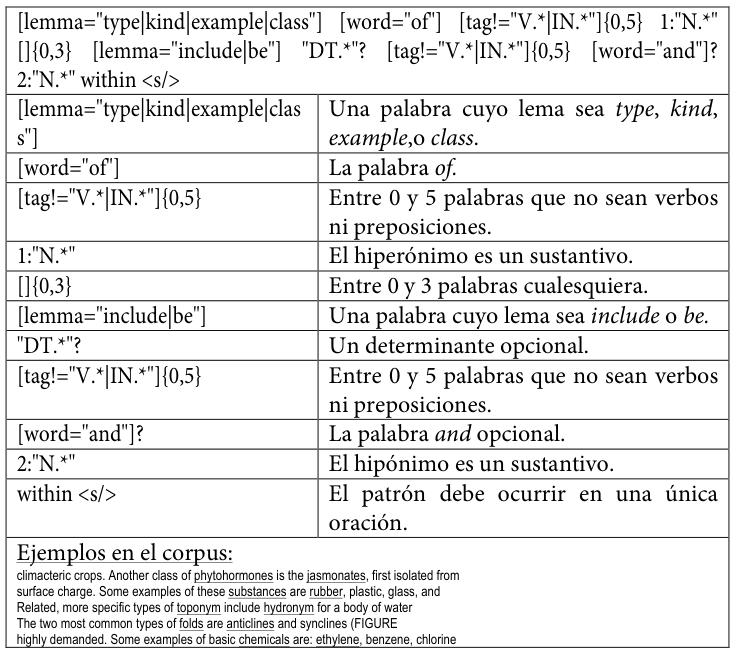
Tabla 20. Segundo patrón de conocimiento hiperonímico codificado para SketchEngine
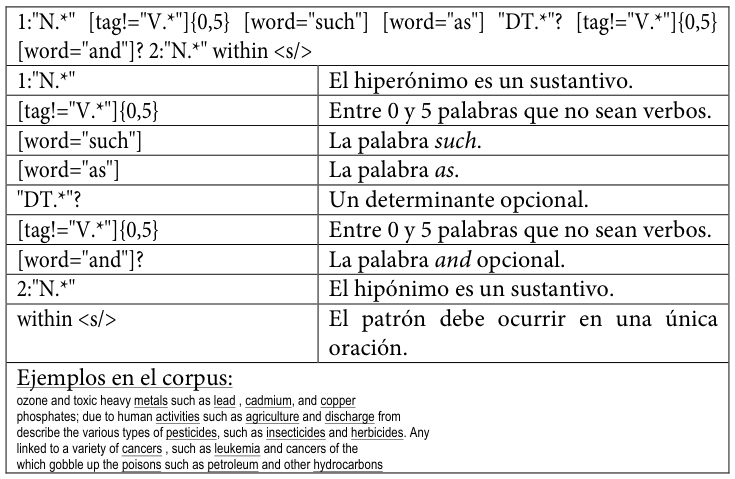
Tabla 21. Tercer patrón de conocimiento hiperonímico codificado para SketchEngine
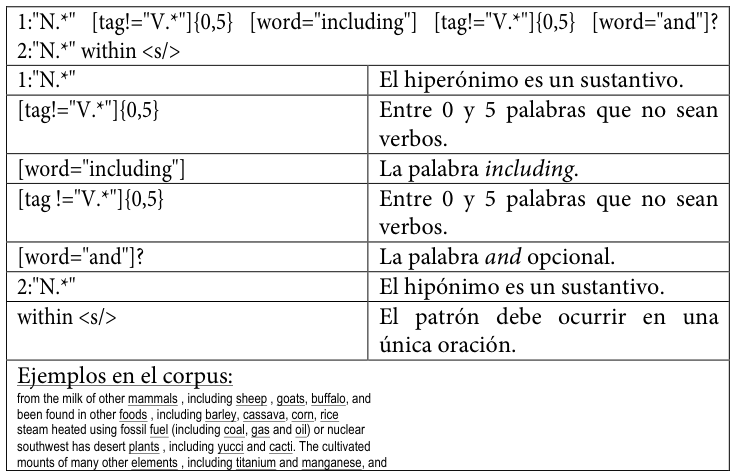
Tabla 22. Cuarto patrón de conocimiento hiperonímico codificado para SketchEngine
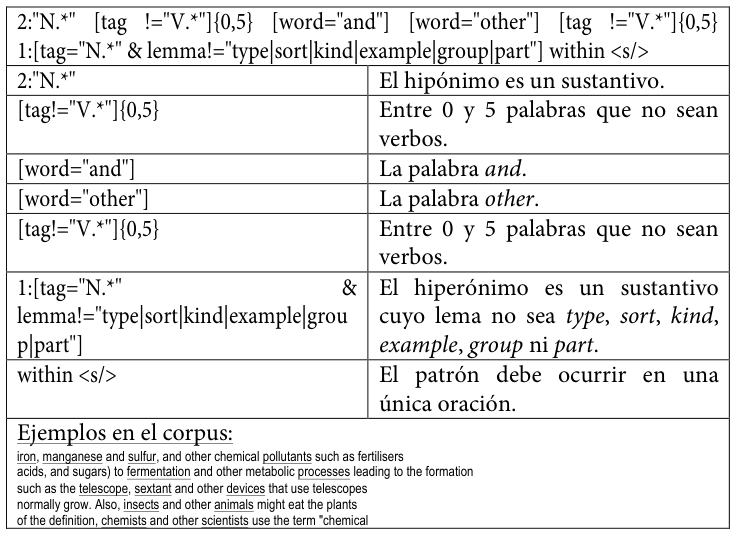
Tabla 23. Quinto patrón de conocimiento hiperonímico codificado para SketchEngine
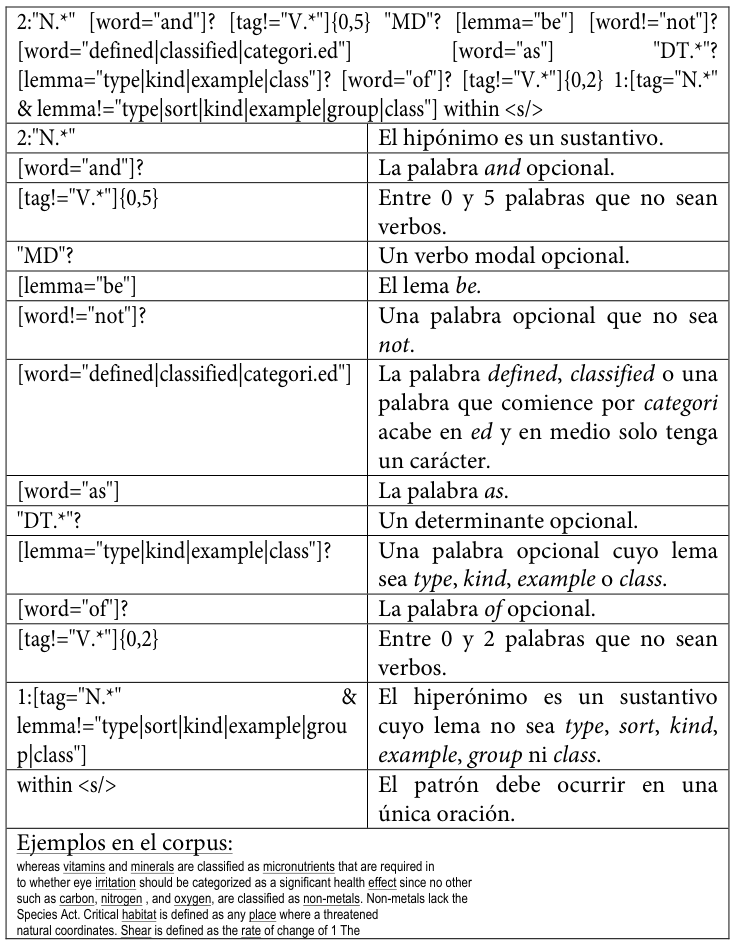
Tabla 24. Sexto patrón de conocimiento hiperonímico codificado para SketchEngine

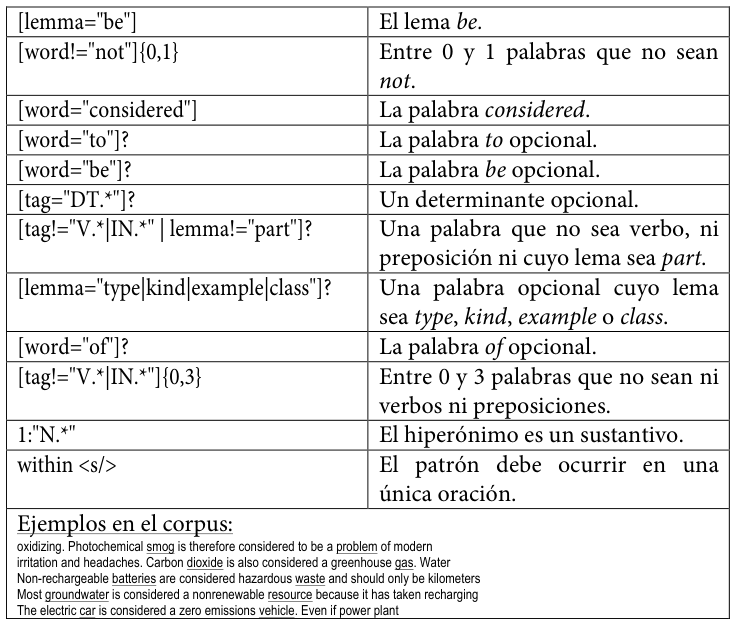
Tabla 25. Séptimo patrón de conocimiento hiperonímico codificado para SketchEngine
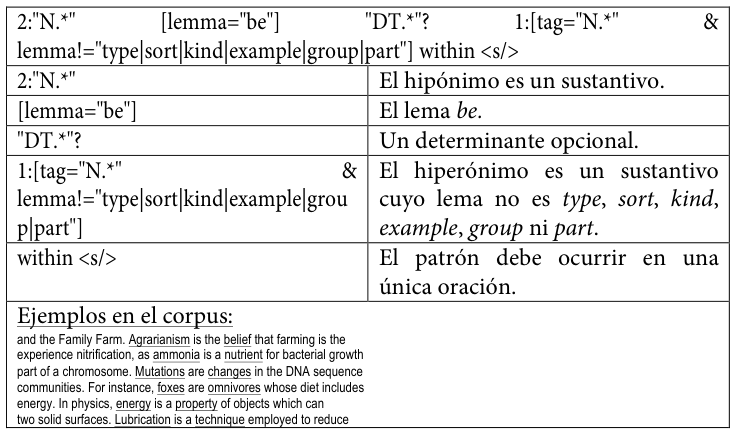
Tabla 26. Octavo patrón de conocimiento hiperonímico codificado para SketchEngine
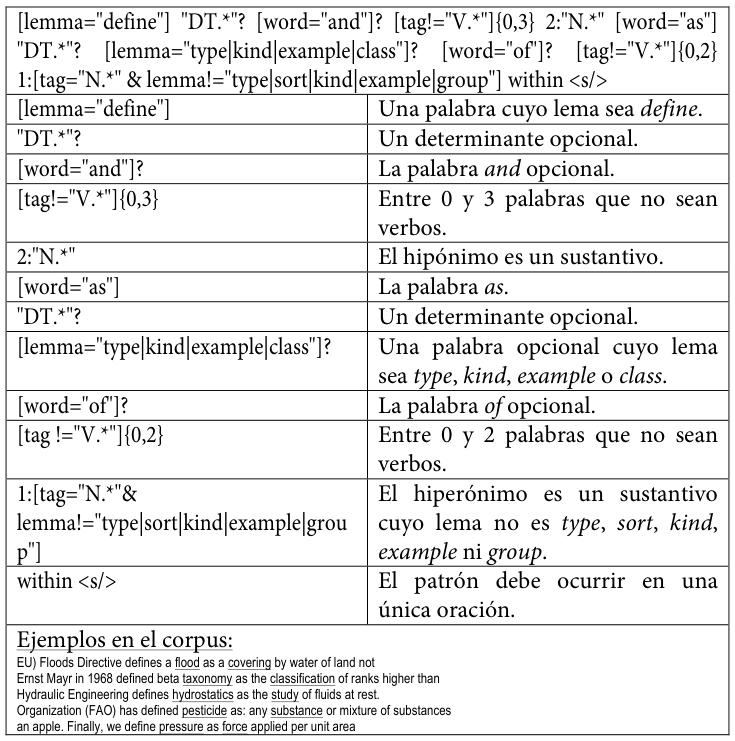
Tabla 27. Noveno patrón de conocimiento hiperonímico codificado para SketchEngine
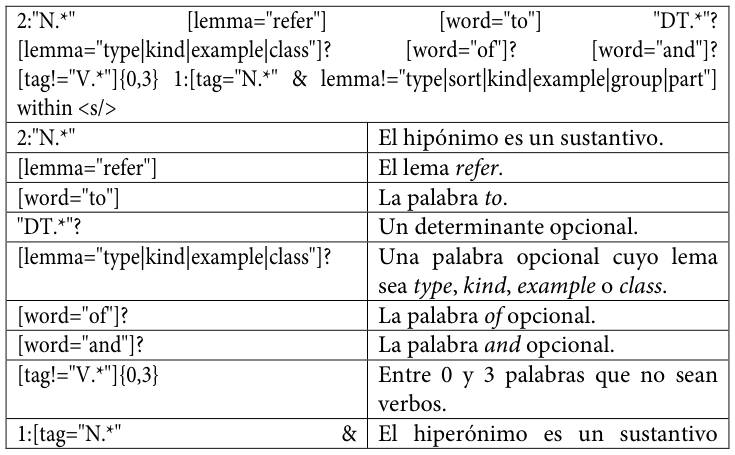

Tabla 28. Décimo patrón de conocimiento hiperonímico codificado para SketchEngine
4.2.2.3.2. La extracción de contextónimos
Los contextónimos (Ji, Ploux y Wehrli 2003; Ji y Ploux 2003) de una unidad léxica son aquellas otras unidades léxicas con las que tiende a coocurrir en contextos lingüísticos. El contexto lingüístico puede abarcar desde una ventana de pocas palabras a varios párrafos. La relación de contextonimia no es ni transitiva (p. ej, que silla sea contextónimo de mesa y que respaldo sea contextónimo de silla, no implica que respaldo sea contextónimo de mesa) ni simétrica (p. ej., que fuego sea contextónimo de mechero no implica que mechero lo sea de fuego). Además, los contextónimos, a diferencia de sinónimos y antónimos, no son necesariamente de la misma categoría gramatical (Ji, Ploux y Wehrli 2003: 195).
La noción de contextónimo parte de la base de que las palabras relacionadas contextualmente con otra palabra señalan de manera significativa el valor semántico de dicha palabra en un contexto dado (Ji, Ploux y Wehrli 2003: 194). De hecho, como se vio en §3.5.3.2.1, el contexto lingüístico es un factor elemental en el proceso por el cual el potencial semántico de una unidad léxica da lugar a un significado concreto.
En este trabajo, se utilizó la noción de contextónimo para determinar qué rasgos semánticos activan un concepto dado según el dominio contextual. Para extraer las listas de contextónimos de un término, utilizamos SketchEngine. Creamos el word-sketch reproducido en la Tabla 29, a partir del cual un contextónimo de una palabra clave es cualquier verbo, sustantivo o adjetivo (excepto los lemas be, have, such, other, much, many, more, do, make, another, mostEsos lemas se excluyeron tras observar en pruebas iniciales que ocupaban habitualmente los primeros lugares de las listas de contextónimos y que nunca transmitían una relación concreta ni significativa con respecto a la palabra clave en las concordancias correspondientes.) que se encuentre antes o después de la palabra clave con entre cero y 44 palabras entre ellos.
La ventana de 44 palabras se determinó a partir del estudio que se describe en San Martín (2014). En dicho estudio, se realizó una comparación entre una lista de referencia compuesta por una lista de términos extraídos con TermoStat Web 3.0 a partir de un corpus de 133 definiciones en inglés de MAGMA y listas de términos extraídas a partir de cinco corpus compuestos de líneas de concordancia del término magma de longitud variable.

Tabla 29. Word-sketch creado para extraer contextónimos
Para reducir la interferencia por la variación terminológica, los términos de la lista de referencia se agruparon en 23 categorías según la proposición conceptual expresada en relación con MAGMA.
La longitud de las concordancias de los corpus era respectivamente: 1) 100 caracteres antes y después de magma; 2) 250 caracteres antes y después de magma; 3) 500 caracteres antes y después de magma; 4) 750 caracteres antes y después de magma. El quinto corpus contenía solo oraciones en las que aparecía magma. La comparación con la lista de referencia se hizo con los 50 y los 100 términos más frecuentes de cada lista.
El resultado del estudio indicó que la lista que presentaba mayor precisión y exhaustividad en comparación con la lista de referencia era la de los 100 términos más frecuentes extraídos a partir del corpus de concordancias de 250 caracteres antes y después de magma.
Dado que una lista de términos extraída de un corpus de concordancias es en gran medida equivalente a una lista de contextónimos para un término especializado, se asumió la ventana de 250 caracteres como parámetro para configurar la extracción de contextónimos. Para calcular el equivalente en palabras de 250 caracteresLa necesidad de utilizar un número de palabras en vez de un número caracteres se debe a una limitación de SketchEngine., se dividió 250 por el número de caracteres de media de las palabras contenidas en el corpus MULTI (5,52), lo cual dio como resultado (redondeado) 45 palabrasEn el word-sketch se estableció la ventana de 44 palabras en vez de 45 porque los 250 caracteres de las concordancias en el estudio de San Martín (2014) incluyen los caracteres del contextónimo..